缓存
想象一下,你正在修理机器,但是现在手上的工具不能转动这个螺母,你需要拿一把合适的工具替代手上的,完成接下来的工作。但是问题是,现在桌子上,工具箱里,货架上都有合适的工具,他们到你的距离是逐渐增加的,为了提高效率,你无疑会去选择拿桌子上那一把工具。

如果旁边有个人当你的小助手,他比较熟悉修理的基本功,所以他知道面对什么零件用什么工具。当你需要换工具时,他会提前找到最近的,然后恰到好处的递给你,或者根据一些工具的使用频率,选择工具放在离你最近的桌子上,那你就可以把大多数时间花在修理机器而不是找工具。
缓存组成层次
之前我们提到修理的例子,其实在计算机也有相同的场景。我们计算机拥有不同级别的缓存,如一级缓存,往往速度最快,但是容量最小,然后是二级缓存。cpu如果可以从一级缓存获得它所需的数据,那么对于cpu来说是非常幸福的,毕竟不用花更多的时间到二级缓存甚至是最慢的主存中寻找需要的数据。而且缓存有LRU(最近最少使用)策略,如果数据很久没被访问,那么缓存中的数据将会被刷新。
数据传输
![]() 数据传输
数据传输
主存和缓存
主存和缓存之间的数据传输,以缓存行为最小单位
缓存和处理器核心
缓存和处理器核心之间的数据传输,以字为最小单位
缓存命中与缓存失效
实验
查询实验所用计算机缓存
# 操作系统:ubuntu22.04
# 列出CPU信息
lscpu
| 缓存 | 容量 |
|---|---|
| L1d | 448KiB |
| L1i | 640KiB |
| L2 | 9MiB |
| L3 | 18MiB |
实验代码
计时器类:
// 在一个作用域内使用,在生命周期结束后,将会输出时间差
// 不支持线程安全
class Timer{
public:
Timer(std::string name):
name_(name)
{
time_stamp_ = std::chrono::high_resolution_clock::now();
}
Timer() = delete;
~Timer()
{
auto time_diff = std::chrono::high_resolution_clock::now() - time_stamp_;
std::cout<< name_ << " operation cost time:\t"
<< std::chrono::duration_cast<std::chrono::milliseconds>(time_diff).count()
<<" ms: \t"<<std::endl;
}
private:
std::string name_;
std::chrono::system_clock::time_point time_stamp_;
};
逐行访问元素:
void read_row(int rows,int cols,int *data,int iter)
{
int total{0};
Timer timer("Row Redaer");
// FULL_BARRIER();
for( int count = 0; count < iter; count++)
for( int row = 0; row < rows; row++)
{
for( int col = 0; col < cols; col++)
{
total += data[row*cols+col];
}
}
// FULL_BARRIER();
NOTOPTIMIZE(total);
}
逐列访问元素:
void read_col(int rows,int cols,int *data,int iter)
{
int total{0};
Timer timer("Colum Redaer");
// FULL_BARRIER();
for( int count = 0; count < iter; count++)
for( int col = 0; col < cols; col++)
{
for( int row = 0; row < rows; row++)
{
total += data[row*cols+col];
}
}
// FULL_BARRIER();
NOTOPTIMIZE(total);
}
主函数部分:
int main() {
// 申请比L1缓存容量大一些的内存
void *data = std::aligned_alloc(32,24000 * 1024);
//
//
int cols = (50*1024) /sizeof(int);
int rows = 480;
int *ptr = static_cast<int *>(data);
for( int row = 0; row < rows; row++)
{
for( int col = 0; col < cols; col++)
{
ptr[row*cols+col] = row*col+col;
}
}
read_col(rows,cols,ptr, 1000);
//read_row(rows,cols,ptr, 1000);
std::free(data);
return 0;
}
编译与运行:
# 赋予内核态的权限
sudo sh -c "echo -1 > /proc/sys/kernel/perf_event_paranoid"
# 编译源文件,选择无优化选项
g++ -O0 -fno-omit-frame-pointer -std=c++17 exercise/cache_performence.cpp -o perf_test
# 使用pref进行分析
perf stat -e L1-dcache-loads,L1-dcache-load-misses,LLC-loads,LLC-load-misses,mem-loads ./perf_test
实验结果分析
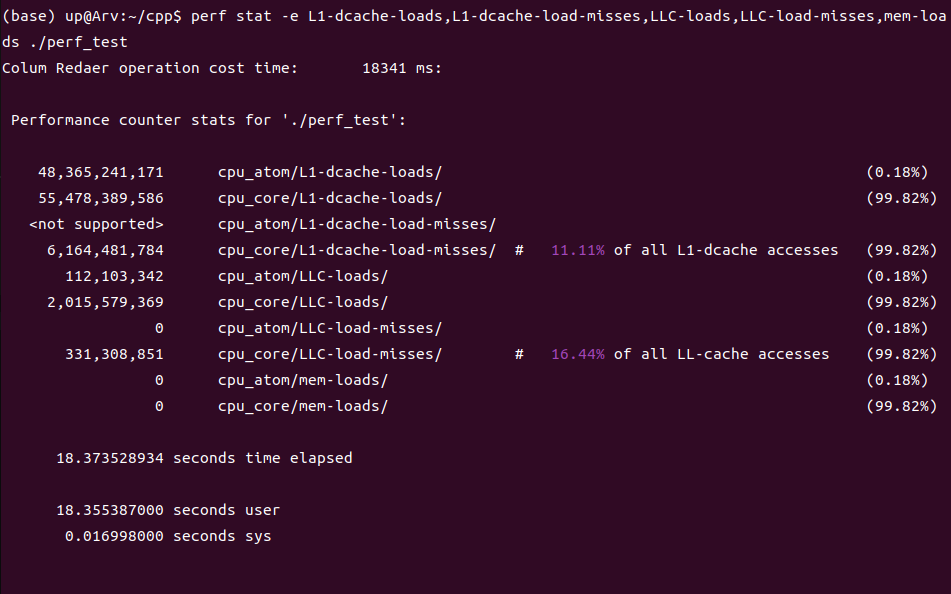
按行访问:
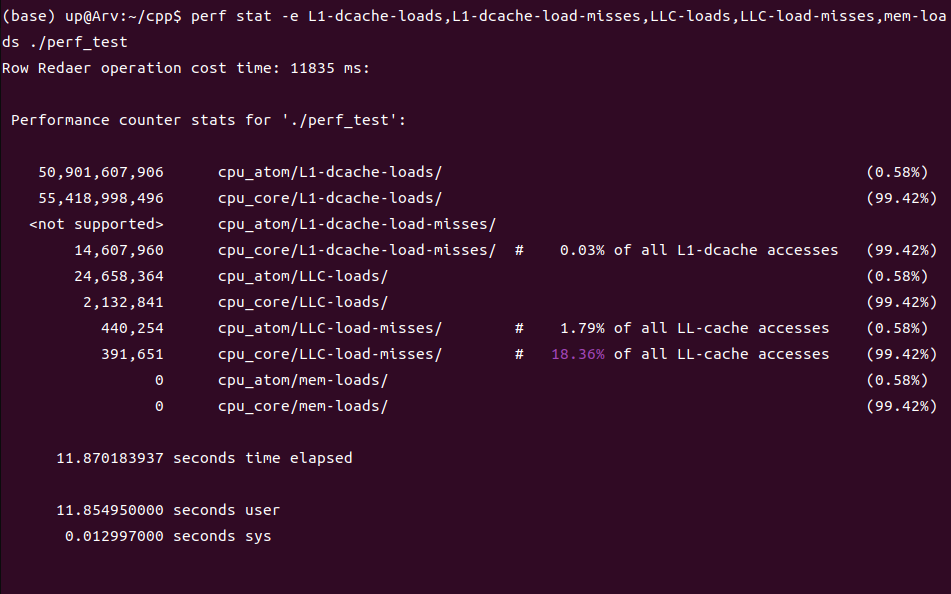
按列访问: